In today’s data-driven landscape, efficient document processing is a key element for businesses striving to enhance productivity and streamline operations. Amazon Textract, a powerful AWS service, offers a solution to extract text and data from documents at scale. In this blog post, we’ll explore challenges related to record-keeping, Amazon Textract’s capabilities, pricing models, and lastly a a robust reference architecture that provides a serverless, highly available, and scalable solution.
The Significance of Documents: Cornerstones of Record-keeping and Efficiency Across Industries
Record-keeping
Documents serve as a primary means of recording information. They allow organizations to keep a detailed history of transactions, communications, and important events. This historical data is often crucial for audits, compliance, and decision-making.
Communication
Documents facilitate effective communication both within organizations and with external parties. From emails and reports to contracts and invoices, documents convey critical information, ensuring that everyone is on the same page.
Collaboration
In collaborative environments, documents provide a shared space for teams to work together. Collaboration tools and document management systems enable multiple people to contribute, edit, and comment on documents in real time.
Transactions
Documents are essential for legal and financial transactions. Contracts, purchase orders, invoices, and receipts are just a few examples of documents that formalize agreements and payments.
The Need for Processing Documents
Search and Discovery
In many organizations, documents are stored in vast quantities, making it challenging to find specific information when needed. This can lead to inefficiencies and delays in decision-making.
Compliance and Control
In regulated industries such as finance, healthcare, and legal, maintaining compliance with industry-specific standards and regulations is crucial. Failing to do so can result in severe consequences.
Business Process Automation
Many business processes involve the manual handling of documents, which can be time-consuming and error-prone. Automation is crucial for increasing efficiency.
Challenges with Processing Documents
Let’s briefly discuss the challenges associated with processing documents within the context of these specific examples.
16.3 Million US Mortgage Applications in 2016 ($2.1 Trillion)
Document Volume: Handling such a large volume of mortgage applications generates massive amounts of paperwork, including income statements, credit reports, and property documents.
Data Extraction: Extracting relevant information from these documents manually can be time-consuming, error-prone, and costly.
Data Accuracy: Ensuring the accuracy of data is crucial in the mortgage industry to avoid financial and legal complications.
Processing Time: Manual document processing can significantly extend the time it takes to approve mortgage applications, potentially causing delays in the home-buying process.
About 240 Million W-2 Tax Forms for FY 2018 in the US
Seasonal Peaks: Tax season in the US sees a massive influx of W-2 forms, creating peak periods of document processing.
Data Security: Tax forms contain sensitive personal and financial information, making data security a paramount concern.
Regulatory Compliance: Processing tax documents requires strict adherence to tax regulations to ensure accurate reporting and compliance.
Resource Intensiveness: Manual entry and validation of data from W-2 forms can be resource-intensive and prone to human error, particularly during peak tax filing periods.
How Documents Are Processed Today?
Manual Processing
Involves human operators reading and extracting information from documents.
Time-consuming and labor-intensive. Prone to errors due to fatigue and inconsistency.
With OCR (Optical Character Recognition)
Uses technology to recognize and convert printed or handwritten text into machine-readable text.
Enables automation but is generally limited to simpler documents. Provides a basis for further automated processing.
Rules and Template-based Extraction
Involves defining rules and templates to extract specific data points from documents.
Offers a semi-automated approach. Effective for structured documents with a consistent layout.
Challenges for Processing Documents
Challenges for Processing Documents with Manual Processing
High labor costs associated with manual data entry. Human errors such as typos and Misinterpretation and slower processing times impact overall efficiency.
Challenges for Processing Documents with Optical Character Recognition
Limited to Simple Documents Only.
OCR may struggle with complex layouts, varied fonts, or handwritten text.
Misinterpretation of characters, especially in noisy or degraded documents.
OCR might treat the document as a flat set of words without understanding the context or structure.
Challenges for Processing Documents with Rules and Template-based Extraction
Highly reliant on documents having a standardized and consistent layout. Difficulty Handling Variability and struggles with documents that deviate from predefined templates. Maintenance Overhead, Regular updates are required for changing document formats or rules.
What Problem Does Amazon Textract Solve?
Amazon Textract is a service provided by Amazon Web Services (AWS) that solves the problem of extracting structured data from documents. Traditional methods of document processing often involve manual data entry, which is time-consuming, error-prone, and costly. Amazon Textract addresses these challenges by leveraging advanced machine learning and optical character recognition (OCR) technologies to automatically extract text, forms, and tables from a variety of documents.
Key Problems that Amazon Textract Solves:
Automated Data Extraction: Textract automates the extraction of text, key-value pairs, tables, and forms from scanned documents, PDFs, and images. This reduces the need for manual data entry, saving time and resources.
Handling Document Variety: Textract is designed to handle a wide range of document types, including invoices, contracts, medical records, and more. It adapts to different layouts and formats, making it versatile for various industries.
Eliminating Manual Effort: By automating the document extraction process, Textract reduces the need for manual labor, minimizing errors associated with human data entry.
Scaling Document Processing: Textract allows organizations to scale their document processing capabilities without a proportional increase in human resources. This is especially crucial for businesses dealing with large volumes of documents.
Integrating with Workflows: Textract integrates seamlessly with other AWS services, making it easy to incorporate automated document processing into existing workflows and applications.
Structured Data Output: Textract doesn’t just provide a flat set of words; it outputs structured data that maintains the relationships between elements, such as tables and forms. This structured output is valuable for downstream processing and analysis.
Adapting to Changes: Textract is designed to adapt to changes in document layouts and formats, reducing the maintenance overhead associated with rule-based or template-based approaches.
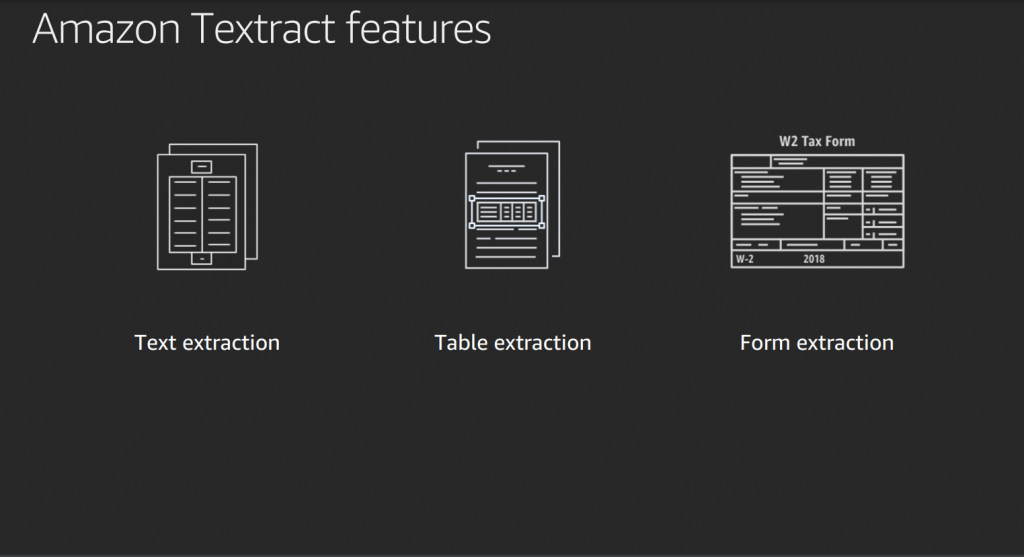
How It Works
Textract utilizes advanced optical character recognition (OCR) technology to accurately recognize and extract textual content. Supports various fonts, sizes, and styles, making it versatile for diverse document layouts.
Benefits: Textract reduces the need for manual data entry by automating the extraction of textual information. It enables the conversion of scanned documents into machine-readable and searchable text.
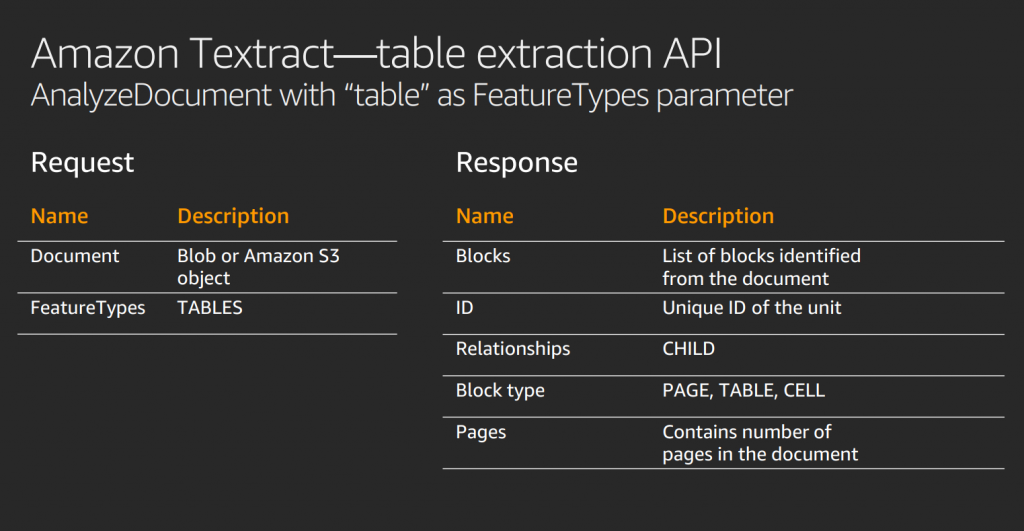
Table Data Extraction with Textraction
Overview: Textract is equipped to identify and extract tabular data from documents, such as financial reports, spreadsheets, and forms.
How It Works: Recognizes the structure of tables, including rows and columns, to accurately extract data points. Outputs structured data that preserves the relationships within tables.
Benefits: Automates the extraction of tabular data, saving time and reducing errors associated with manual extraction.
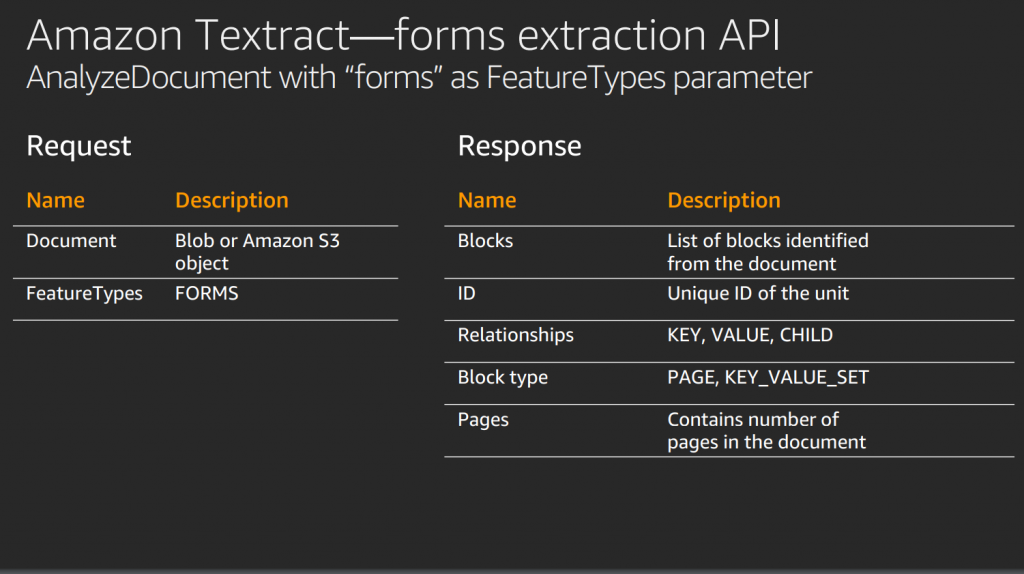
Form Data Extraction with Textraction
Overview: Textract is capable of identifying and extracting data from forms, such as surveys, questionnaires, and application forms.
How It Works: Recognizes form fields, checkboxes, and other elements to extract relevant information. Maintains the context of the extracted data within the form structure.
Benefits: Streamlines the processing of forms by automating data extraction. Enables businesses to efficiently handle large volumes of form-based data.
Amazon Textract: Overall Advantages
Versatility: Versatility Amazon Textract is versatile and can handle a wide range of document types, adapting to different layouts and formats.
Scalability: Allows organizations to scale their document processing capabilities without a proportional increase in a manual effort.
Structured Data Output: Provides structured output that maintains relationships between elements, facilitating downstream processing and analysis.
Integration with AWS Services: Easily integrates with other AWS services, making it seamless to incorporate Textract into existing workflows and applications.
The Diverse Arsenal of Amazon Textract APIs
AnalyzeDocument API: This API stands as the cornerstone of Textract’s capabilities, delving into document analysis with finesse. It extracts not only text but also handwriting, tables, and other forms of data. From PDFs to intricate documents, AnalyzeDocument empowers you to unlock structured information seamlessly.
AnalyzeSpend API: Tailored for financial intricacies, AnalyzeSpend steps into the realm of invoices and receipts, deciphering and extracting spending data. It’s a game-changer for businesses seeking to streamline financial workflows and generate comprehensive spending reports.
DetectDocumentFeatures API: Understanding a document’s nuances is vital, and that’s precisely what DetectDocumentFeatures accomplishes. From document type identification to assessing page count and text orientation, this API equips you with valuable insights into the nature of the documents you’re handling.
GetDocumentAnalysis API: In the dynamic landscape of document processing, retrieval is paramount. GetDocumentAnalysis allows you to fetch the results of a prior AnalyzeDocument call. This retrieval capability is invaluable for updating databases, generating detailed reports, or refining subsequent processing steps.
GetDocumentText API: Digging into the extracted textual content, GetDocumentText enables the retrieval of text gleaned from a document during a previous AnalyzeDocument call. This API is particularly handy when focusing solely on textual information without the broader document analysis.
StartDocumentAnalysisJob API: For scenarios demanding asynchronous document analysis on a large scale, StartDocumentAnalysisJob takes center stage. By initiating an asynchronous job, this API ensures efficient processing of a substantial volume of documents, freeing up resources for other critical tasks.
StartSpendAnalysisJob API: Parallel to its document-centric counterpart, StartSpendAnalysisJob is geared toward the asynchronous analysis of spend-related documents, especially invoices and receipts. It’s a strategic choice for organizations dealing with significant financial documentation.
Real-World Applications of Amazon Textract APIs
Empowering Database Enrichment with AnalyzeDocument
Utilize the AnalyzeDocument API to seamlessly extract text from PDF documents and enrich your database. This not only ensures data accuracy but also accelerates the process of updating and maintaining comprehensive records.
Financial Transparency with AnalyzeSpend
In the financial domain, AnalyzeSpend has become a strategic ally. Extract spend data from a stack of invoices and receipts, weaving it into a detailed report that provides a transparent view of financial transactions.
Precision Document Identification with DetectDocumentFeatures
Understanding the nature of documents is pivotal. DetectDocumentFeatures aids in identifying document types, counting pages, and assessing text orientation. This knowledge is foundational for subsequent processing steps tailored to specific document characteristics.
Seamless Integration of Results with GetDocumentAnalysis
Retrieval of document analysis results is seamless with GetDocumentAnalysis. This API allows you to fetch prior results and integrate them into your workflow, ensuring that your databases and reports stay updated with the latest insights.
Scalable Document Processing with StartDocumentAnalysisJob
Efficiency in processing a large number of documents is a hallmark of StartDocumentAnalysisJob. By initiating asynchronous document analysis jobs, this API optimizes resource utilization, making it an ideal choice for organizations dealing with voluminous document flows.
Streamlining Financial Workflows with StartSpendAnalysisJob
Efficiency in processing a large number of documents is a hallmark of StartDocumentAnalysisJob. By initiating asynchronous document analysis jobs, this API optimizes resource utilization, making it an ideal choice for organizations dealing with voluminous document flows.
Streamlining Financial Workflows with StartSpendAnalysisJob
For businesses navigating a sea of invoices and receipts, StartSpendAnalysisJob offers a lifeline. By initiating asynchronous spend analysis jobs, this API streamlines financial workflows, ensuring accurate data extraction and reporting even in the face of substantial document volumes.
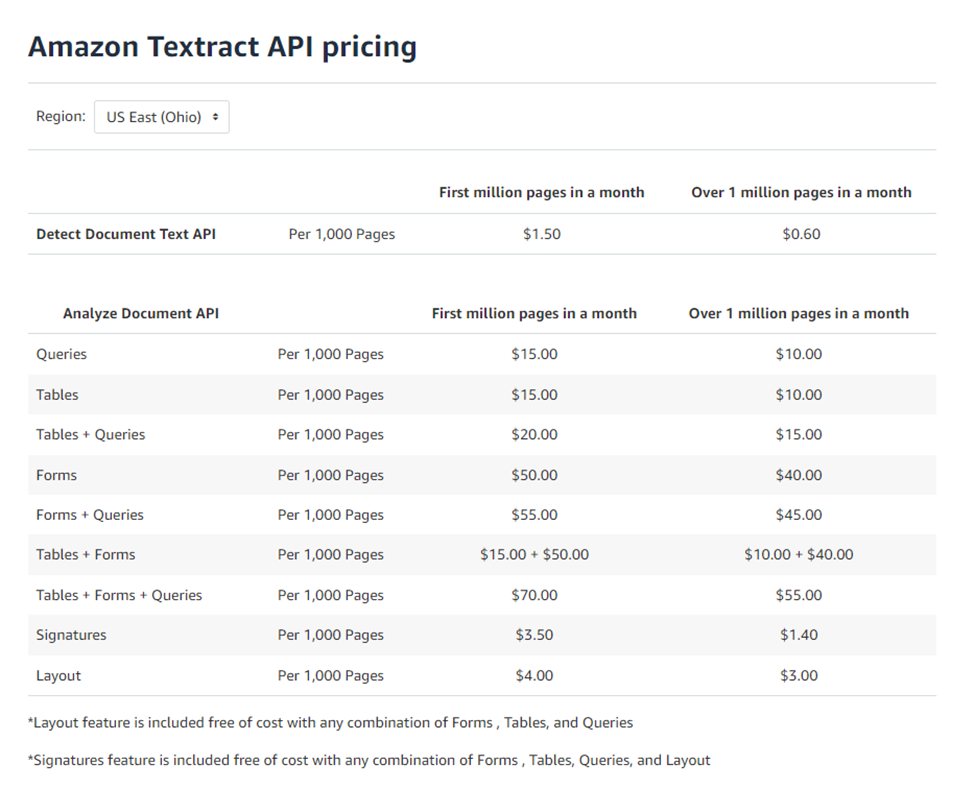
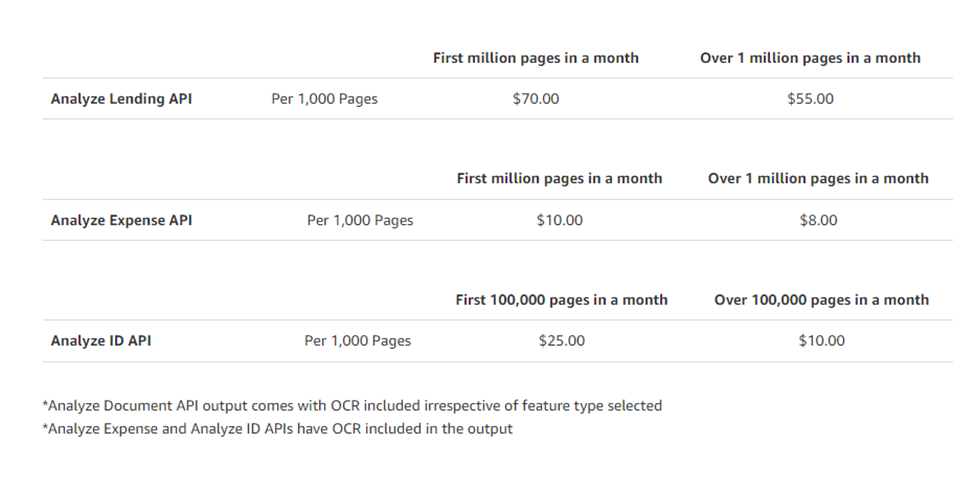
Navigating Amazon Textract Pricing
Amazon Textract offers a range of APIs catering to diverse document processing needs, each with its pricing structure. Let’s dive into various pricing examples outside the free tier to shed light on potential costs.
Pricing Example 1 – Detect Document Text API
Suppose you aim to extract text from 100,000 pages of research reports using the Detect Document Text API. In the US West (Oregon) region, the pricing per page for the first one million pages is $0.0015, resulting in a cost of $150.
Total pages processed: 100,000
Price per page: $0.0015 Total charge: $0.0015 * 100,000 = $150
Pricing Example 2 – Detect Document Text API
Expanding the scenario, let’s extract text from two million pages. The pricing for the first one million pages remains $0.0015, and for pages after one million, it’s $0.0006. The total cost for two million pages would be $2,100.
Total pages processed: 2,000,000
Price per page: $0.0015 for the first 1 million, $0.0006 after 1 million
Pricing Example 3 – Analyze Document API – Forms and Tables
Suppose you want to extract text and structured data from 5,000 pages of tax forms using the Analyze Document API. The pricing per page for one million pages with tables is $0.015, and with forms is $0.05, resulting in a total cost of $325.
Total pages processed: 5,000.
Price for page with table: $0.015
Price for page with form (key-value pair): $0.05 Total charge: $0.015 * 5,000 + $0.05 * 5,000 = $75 + $250 = $325
Pricing Example 4 – Analyze Document API – Forms and Tables
Expanding the document count to two million pages, with varied pricing after the first million, results in a total cost of $115,000.
Total pages processed: 2,000,000
Price for page with form (key-value pair): $0.05 for the first 1 million, $0.04 for the next 1 million
Pricing Example 5 – Analyze Document API – Queries
If you want to extract text from 5,000 pages of mortgage forms and also extract 10 specific data points from each page via Queries, the total cost would be $75.
Total pages processed: 5,000
Price per page with Queries: $0.015
Total charge: $0.015 * 5,000 = $75
Pricing Example 6 – Analyze Document API – Forms and Tables and Queries
For extracting text, forms, and tables from two million pages of pay stubs, along with 10 specific data points via Queries, the total cost would be $125,000.
Total pages processed: 2,000,000
Price for page with Tables, Forms, and Queries: $0.070 for the first one million, $0.055 for the next one million
Pricing Example 7 – Analyze Document API – Forms and Queries
For extracting text and table data from 5,000 pages of tax forms and extracting 10 specific data points via Queries, the total cost would be $100.
Total pages processed: 5,000
Price for page with table and Queries: $0.020
Total charge: $0.020 * 5,000 = $100
Pricing Example 8 – Analyze Document API – Signatures
For detecting signatures and extracting raw text from 100,000 pages of mortgage documents, the cost would be $350.
Total pages processed: 100,000
Price per page: $0.0035
Total charge: $0.0035 * 100,000 = $350
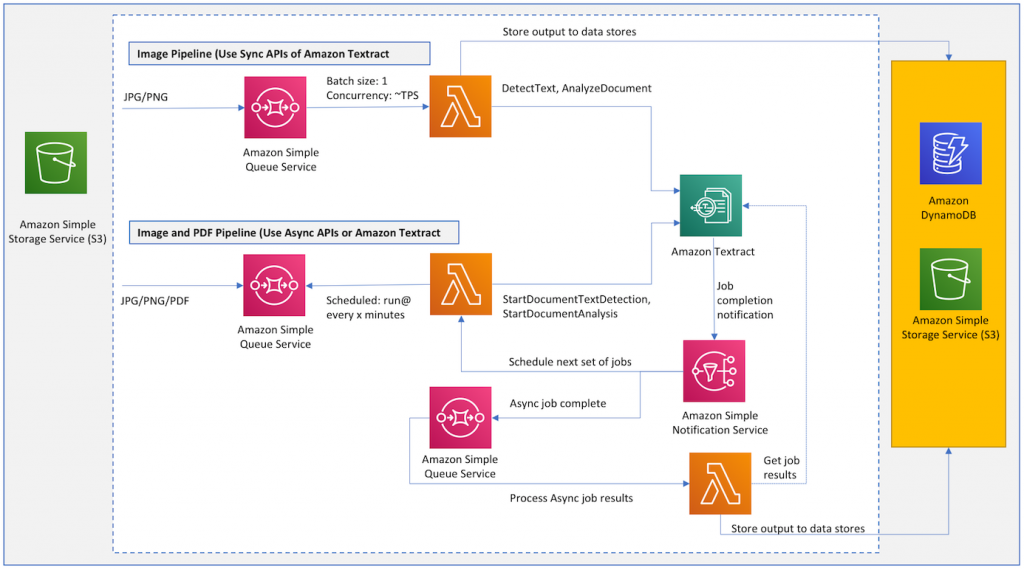
Reference Architecture
Image Source – Google | Large-scale document processing with Amazon Textract
Key Attributes of the Reference Architecture
Processing Documents in Amazon S3
The architecture is designed to efficiently handle incoming documents by processing them through an Amazon S3 bucket. This ensures a seamless flow of documents into the document processing pipeline.
Backfill of Existing Documents
Addressing the need to process a large backfill of existing documents, the architecture extends its capabilities to handle historical data stored in an Amazon S3 bucket. This feature is invaluable for organizations with extensive document archives.
Serverless and Highly Scalable
Embracing a serverless architecture, the solution eliminates the need for managing and provisioning servers. It effortlessly scales to meet varying workloads, ensuring optimal performance even during peak demands.
Spiky Workload Management
The architecture is adept at handling spiky workloads, efficiently accommodating fluctuations in document processing demands. This capability is essential for businesses with dynamic and unpredictable document arrival patterns.
Support for Sync and Async APIs
The reference architecture incorporates pipelines supporting both Sync and Async APIs of Amazon Textract. This flexibility allows users to choose the mode that best aligns with their specific processing requirements.
Controlled Document Processing Rate
A distinctive feature of this architecture is its ability to control the rate at which documents are processed. This control mechanism is crucial for safeguarding downstream systems that ingest output from Textract. It prevents overwhelming downstream systems and ensures a smooth workflow.
Sample Implementation with AWS CDK
The reference architecture showcases a sample implementation using the AWS Cloud Development Kit (CDK). This empowers users to define infrastructure as code, providing a streamlined and reproducible approach. The infrastructure is easily provisioned through AWS CloudFormation.
Unlocking Document Processing at Scale with Amazon Textract: A Comprehensive Guide – Part 2 (Coming Soon)
Conclusion
In summary, Amazon Textract offers a comprehensive set of features for extracting text, tables, and forms from documents, leveraging advanced OCR and machine learning technologies to automate and enhance document processing workflows.
This blog post was written by Afjal Ahamad, a data engineer at QloudX. Afjal has over 4 years of experience in IT, and he is passionate about using data to solve business problems. He is skilled in PySpark, Pandas, AWS Glue, AWS Data Wrangler, and other data-related tools and services. He is also a certified AWS Solution Architect and AWS Data Analytics – Specialty.
[…] our blog series, “Unlocking Document Processing at Scale with Amazon Textract.” In our previous installment, we explored the significance of documents in various industries, identified the challenges […]
Qloudx takes your privacy and security seriously.
We use cookies to collect information about you.
We use this information:
1. to give you a better experience (functional)
2. to count the pages you visit (statistics)
3. to serve you relevant promotions (marketing)
Click “ACCEPT” to give us your consent to use cookies for all these purposes.
Read more about how we use cookies to collect personal data: Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are as essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.





[…] our blog series, “Unlocking Document Processing at Scale with Amazon Textract.” In our previous installment, we explored the significance of documents in various industries, identified the challenges […]