



Athena 101: How to Use Athena to Query Files in S3

Amazon Athena is a fully managed and serverless AWS service that you can use to query data in S3 files using ANSI SQL. Amazingly, it can scale up to petabytes of data while still keeping all your data in S3 itself. Normally you would need something like a data warehouse to do this. You would also need to load the data from S3 into the warehouse to be able to query it. But Athena can query it right there in S3!
So, how does it work?
Since Athena uses SQL, it needs to know the schema of the data beforehand. Athena can work on structured data files in the CSV, TSV, JSON, Parquet, and ORC formats. Once you have defined the schema, you point the Athena console to it and start querying. Simple as that!
In this article, I’ll walk you through an end-to-end example for using Athena. We will start by getting a dataset, uploading it to S3, discover its schema, set up Athena, and finally, query it!
The Dataset
For our sample dataset, we will download an EC2 instances comparison spreadsheet as CSV from EC2Instances.info. If you’ve never been to this site, it’s a great resource for the deepest technical details and pricing of EC2 instances, both standalone and for RDS.
It’s built by scraping a number of official AWS webpages that provide this info. I tried getting this info using a number of AWS CLI commands and quickly realized it’s not easy! Hats off to the guys who built this. Check out their GitHub repo here.
Back to our tutorial, head on over to the site and click the CSV button to download the dataset. If you intend to use the data beyond this tutorial, select the columns, pricing options, etc. from the top menu before downloading:
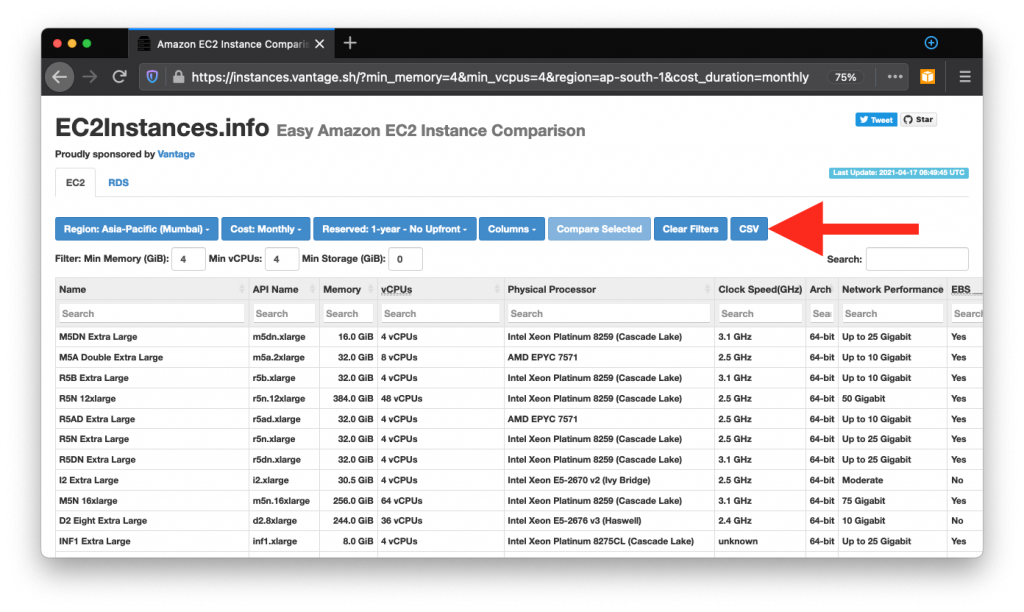
Upload the CSV file you get to an S3 bucket of your choosing.
Schema Discovery
Instead of building the schema by hand, we will use AWS Glue to auto-discover the schema. For this, click here to start creating a Glue Crawler: console.aws.amazon.com/glue/home#addCrawler:. A Glue Crawler “crawls” an S3 location to detect the schema of the data that might be in those files.
For our example, all defaults in the add crawler wizard are OK. The only thing you need to do is to select the S3 location where you uploaded the CSV. Remember to select the folder that contains the CSV, not the CSV itself.
After the crawler is ready, run it by selecting it from the console. Since ours is a small file, it would be done in a couple of minutes. If you check out the Tables section of the Glue console now, you’ll see a new table created for the CSV you uploaded:

Athena Query
We are almost ready to start querying. There is just one last thing to set up. Athena needs an S3 location to save the query results to. This is because Athena queries can potentially run for minutes or hours and the user is not expected to keep the console open to “see” the query results. This is unlike traditional database clients like MySQL Workbench where you send a query, get a result, and discard it. All Athena results are saved to S3 as well as shown on the console.
To set the results location, open the Athena console, and click Settings:
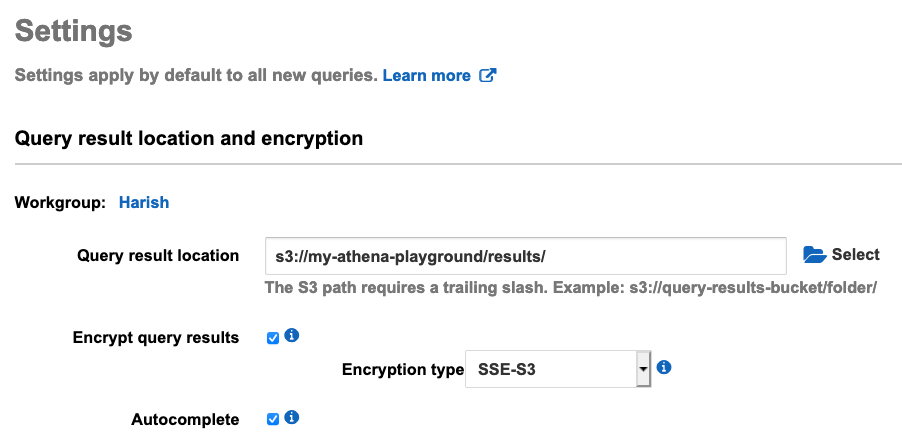
Save this and you’re ready to start issuing queries. Select AwsDataCatalog as the data source, the database where your crawler created the table, and then preview the table data:
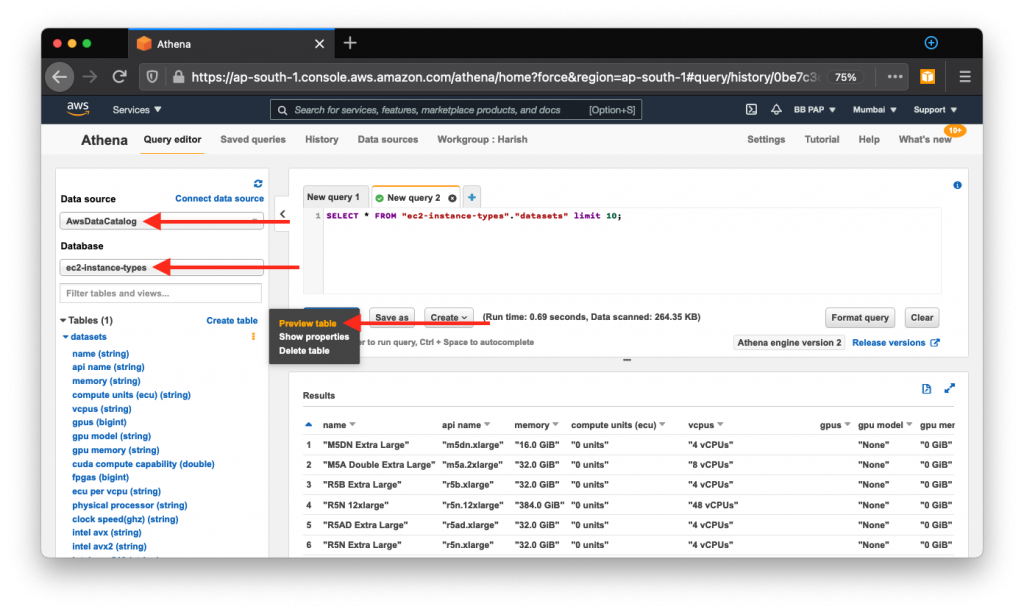
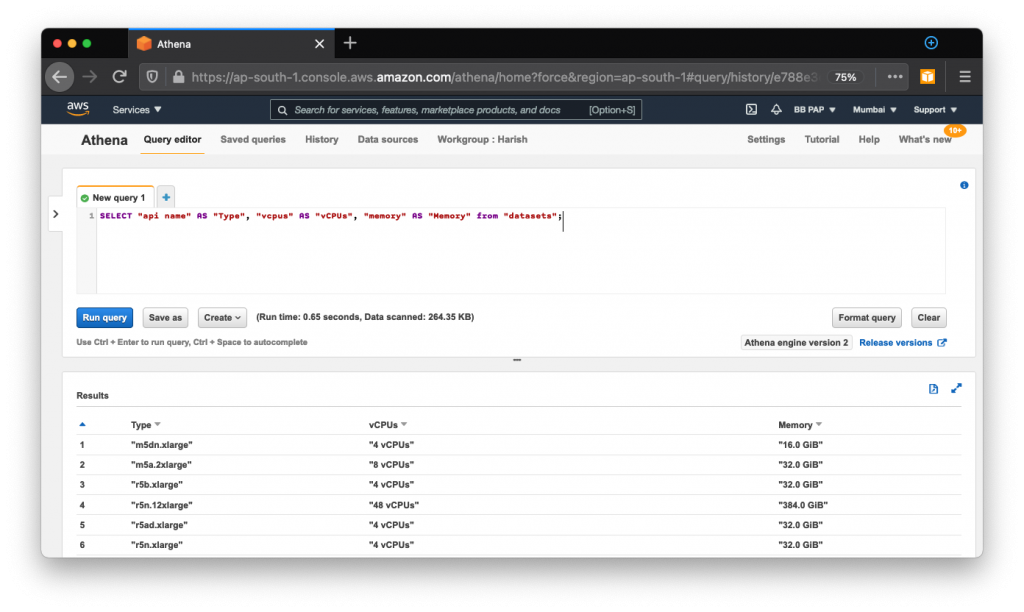
You can now issue ad-hoc queries to analyze your data as needed:
About the Author ✍🏻

Harish KM is a Principal DevOps Engineer at QloudX. 👨🏻💻
With over a decade of industry experience as everything from a full-stack engineer to a cloud architect, Harish has built many world-class solutions for clients around the world! 👷🏻♂️
With over 20 certifications in cloud (AWS, Azure, GCP), containers (Kubernetes, Docker) & DevOps (Terraform, Ansible, Jenkins), Harish is an expert in a multitude of technologies. 📚
These days, his focus is on the fascinating world of DevOps & how it can transform the way we do things! 🚀